Benchmark Workflow
A benchmark in MedPerf is a collection of assets that are developed by the benchmark committee that aims to evaluate medical ML on decentralized data providers.
The process is simple yet effective enabling scalability.
Step 1. Establish Benchmark Committee¶
The benchmarking process starts with establishing a benchmark committee of healthcare stakeholders (experts, committee), which will identify a clinical problem where an effective ML-based solution can have a significant clinical impact.
Step 2. Register Benchmark¶
A benchmark workflow is defined by three containers. A Data Preparator container, a Reference Model container, and a Metrics container, need to be submitted in order to define a benchmark workflow. After submitting the three containers, alongside with a sample reference dataset, the Benchmark Committee is capable of creating a benchmark. Once the benchmark is submitted, the Medperf admin must approve it before it can be seen by other users. Follow our Hands-on Tutorial for detailed step-by-step guidelines.
Step 3. Register Dataset¶
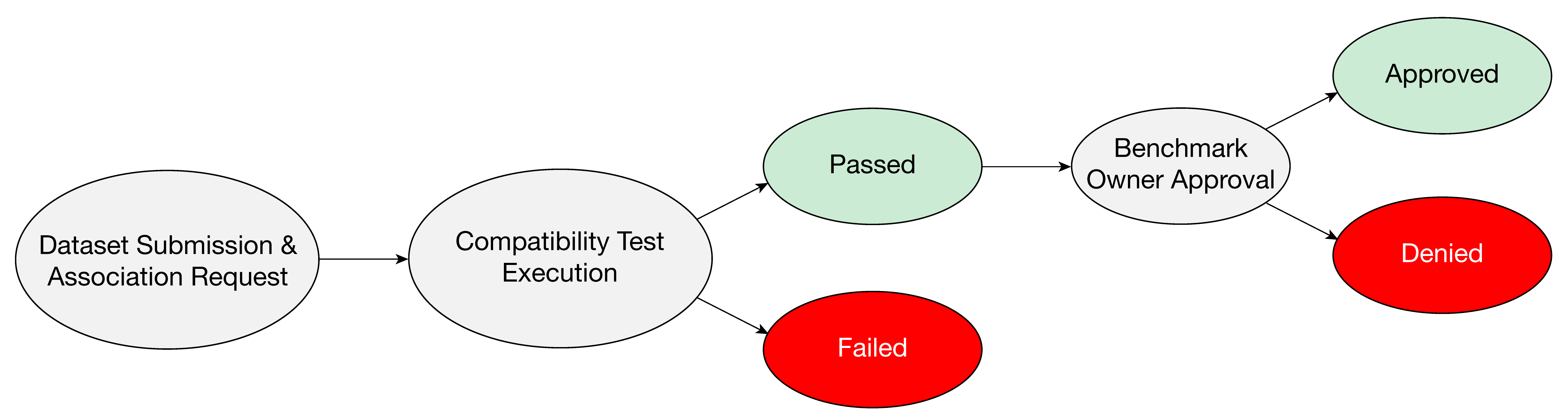
Data Providers that want to be part of the benchmark can register their own datasets, prepare them, and associate them with the benchmark. A dataset will be prepared using the benchmark's Data Preparator container and the dataset's metadata is registered within the MedPerf server.
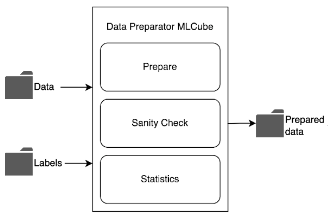 |
|---|
| Data Preparation |
The data provider then can request to participate in the benchmark with their dataset. Requesting the association will run the benchmark's reference workflow to assure the compatibility of the prepared dataset structure with the workflow. Once the association request is approved by the Benchmark Committee, then the dataset becomes a part of the benchmark.
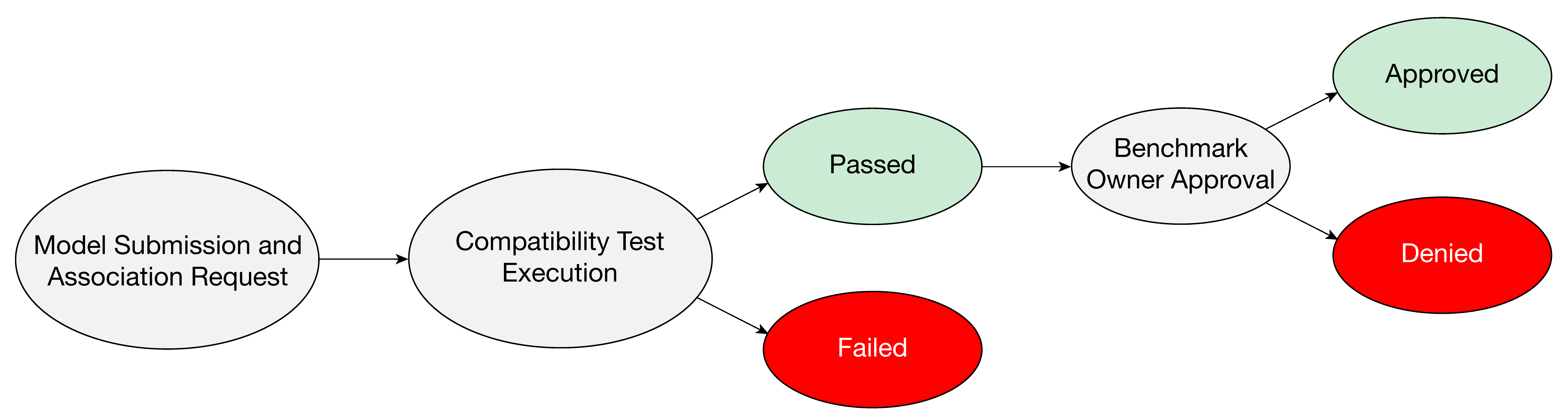
Step 4. Register Models¶
Once a benchmark is submitted by the Benchmark Committee, any user can submit their own Models and request an association with the benchmark. This association request executes the benchmark locally with the given model on the benchmark's reference dataset to ensure workflow validity and compatibility. If the model successfully passes the compatibility test, and its association is approved by the Benchmark Committee, it becomes a part of the benchmark.
Step 5. Execute Benchmark¶
The Benchmark Committee may notify Data Providers that models are available for benchmarking. Data Providers can then run the benchmark models locally on their data.
This procedure retrieves the model containers associated with the benchmark and runs them on the indicated prepared dataset to generate predictions. The Metrics container of the benchmark is then retrieved to evaluate the predictions. Once the evaluation results are generated, the data provider can submit them to the platform.

Step 6. Aggregate and Release Results¶
The benchmarking platform aggregates the results of running the models against the datasets and shares them according to the Benchmark Committee's policy.
The sharing policy controls how much of the data is shared, ranging from a single aggregated metric to a more detailed model-data cross product. A public leaderboard is available to Model Owners who produce the best performances.